The Backbone of a Multi-Agent Organization
Policy and Ontology
Organizations don't fail at AI because models aren't smart enough. They fail because meaning and behavior aren't governed.
A multi-agent setup can quickly become a set of local optimizers: each agent gets better at its own domain, but the organization becomes less coherent. Decisions drift, definitions diverge, and automation starts behaving differently across teams. The result is not an "AI organization" - it's operational noise.
To build multi-agent systems that actually improve performance over time, you need two foundational layers: a central policy layer that governs what agents are allowed to do, how they escalate, and how they stay auditable; and a shared ontology layer that defines what the organization means when it says "customer," "asset," "downtime," "priority," or "service level."
Together, policy and ontology become the organizational operating system - keeping agents aligned end-to-end, even as you scale across domains.
Why Central Policy Is Essential
Agents don't just answer questions - they trigger workflows, recommend actions, route tasks, and influence real decisions. Once you deploy multiple agents across operations, IT, finance, service, manufacturing, or municipal functions, behavior consistency becomes the main risk and the main opportunity.
A central policy layer creates one predictable set of rules for the entire agent ecosystem:
Authority boundaries: what each agent can approve, execute, or only recommend
Escalation rules: when uncertainty, risk, or exceptions must move to a human owner
Data access controls: what systems can be accessed for which purposes
Auditability: what must be logged and why - traceability for decisions and actions
Safety constraints: privacy, security, regulatory requirements, and organizational guardrails
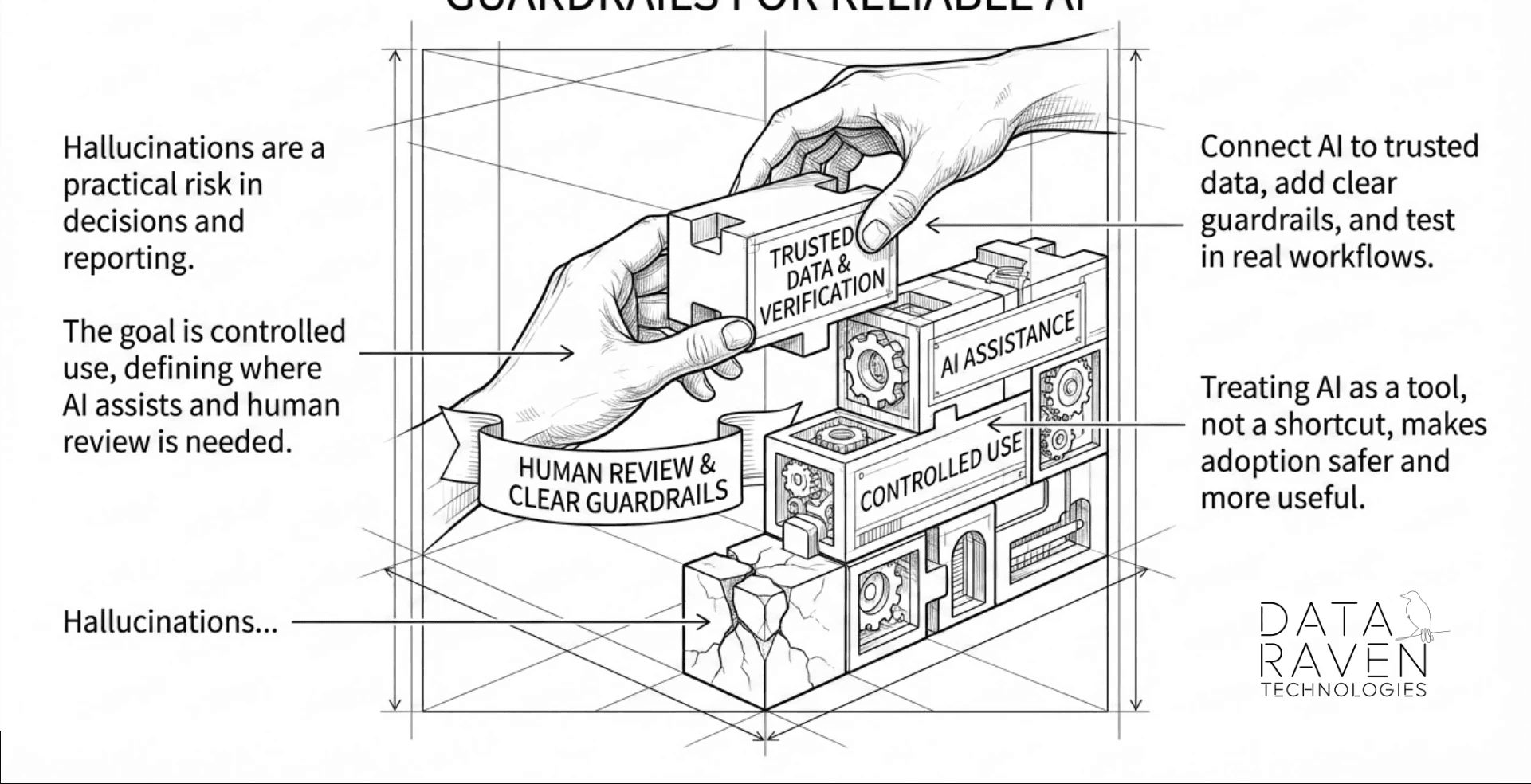
This is how you prevent "shadow automation" and keep AI aligned with real operational reality - especially in environments that can't afford disruptions.
Here's a practical illustration of why policy enables cross-agent collaboration rather than blocking it: a support agent detects a recurring failure pattern and wants to flag it to the R&D team. Without a shared policy layer, it has no reliable way to do that - it doesn't know what format R&D expects, who the right owner is, or whether it's even permitted to write to that system. With a central policy layer, the answer is pre-defined: the support agent is allowed to submit a structured escalation artifact - not a raw action - routed to a named owner, with a required evidence format. The R&D agent picks it up from the same governed queue, already tagged and contextualized. Neither agent needed to know anything about the other. The policy layer handled the handoff. That is what cross-agent collaboration actually looks like in production: not agents talking to each other, but agents operating within shared rules that make their outputs compatible.
Organizations don't fail at AI because models aren't smart enough. They fail because meaning and behavior aren't governed.
A multi-agent setup can quickly become a set of local optimizers: each agent gets better at its own domain, but the organization becomes less coherent. Decisions drift, definitions diverge, and automation starts behaving differently across teams. The result is not an "AI organization" - it's operational noise.
To build multi-agent systems that actually improve performance over time, you need two foundational layers: a central policy layer that governs what agents are allowed to do, how they escalate, and how they stay auditable; and a shared ontology layer that defines what the organization means when it says "customer," "asset," "downtime," "priority," or "service level."
Together, policy and ontology become the organizational operating system - keeping agents aligned end-to-end, even as you scale across domains.
Why Central Policy Is Essential
Agents don't just answer questions - they trigger workflows, recommend actions, route tasks, and influence real decisions. Once you deploy multiple agents across operations, IT, finance, service, manufacturing, or municipal functions, behavior consistency becomes the main risk and the main opportunity.
A central policy layer creates one predictable set of rules for the entire agent ecosystem:
Authority boundaries: what each agent can approve, execute, or only recommend
Escalation rules: when uncertainty, risk, or exceptions must move to a human owner
Data access controls: what systems can be accessed for which purposes
Auditability: what must be logged and why - traceability for decisions and actions
Safety constraints: privacy, security, regulatory requirements, and organizational guardrails
This is how you prevent "shadow automation" and keep AI aligned with real operational reality - especially in environments that can't afford disruptions.
Here's a practical illustration of why policy enables cross-agent collaboration rather than blocking it: a support agent detects a recurring failure pattern and wants to flag it to the R&D team. Without a shared policy layer, it has no reliable way to do that - it doesn't know what format R&D expects, who the right owner is, or whether it's even permitted to write to that system. With a central policy layer, the answer is pre-defined: the support agent is allowed to submit a structured escalation artifact - not a raw action - routed to a named owner, with a required evidence format. The R&D agent picks it up from the same governed queue, already tagged and contextualized. Neither agent needed to know anything about the other. The policy layer handled the handoff. That is what cross-agent collaboration actually looks like in production: not agents talking to each other, but agents operating within shared rules that make their outputs compatible.
Why Ontology Is the Secret to Cross-Domain Scale
Most organizations already have data. What they lack is shared meaning.
Without a common ontology, agents will interpret the same term differently depending on the system or domain they're connected to. That creates silent failures:
"Customer" in CRM ≠ "customer" in billing
"Downtime" in production ≠ "downtime" in maintenance
"Incident" in IT ≠ "incident" in quality
Consider a real case: a product called "Tiger" exists in three systems simultaneously - as a model family in the CRM, as a specific hardware configuration in SAP, and as a software module name in the defect tracking system. An agent pulling context from all three has no way to know these are different things. It will confidently combine information from all three, producing an answer that is internally consistent but factually wrong. No prompt engineering fixes this. The only fix is a shared definition: what "Tiger" means, in which context, and which system is authoritative.
A practical ontology layer solves this by establishing:
A business glossary: canonical terms, synonyms, units, owners
Relationships: entities and how they connect across lifecycle and systems
Rules: KPI definitions, calculation logic, context constraints
Provenance: where numbers come from, when they update, who is accountable
This is why building an organizational data ontology is not "data governance bureaucracy" - it's what enables agents to collaborate across processes without inventing meaning.
The Learning Engine: Procedures That Create a Curve
A multi-agent organization should not be designed as a collection of bots. It should be designed as a learning cycle. That's the difference between short-term automation and long-term capability.
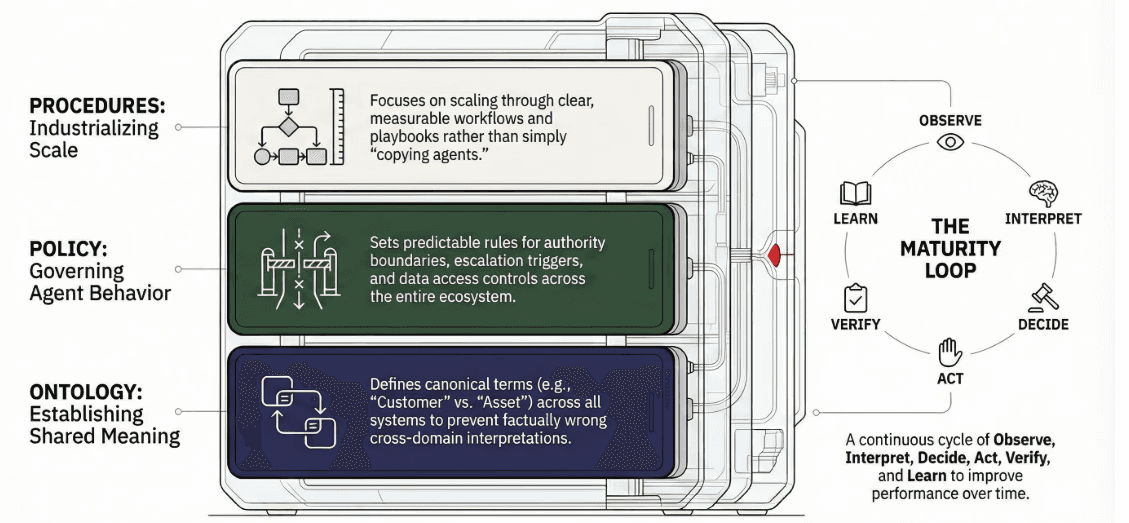
A practical structure is a three-layer stack:
Ontology (Meaning): shared definitions and relationships
Policy (Behavior): guardrails, authority, and auditing
Procedures (Learning & Execution): playbooks and workflows that evolve
Procedures are the scaling unit. When you want to expand to new domains, you don't "copy an agent." You industrialize a procedure: clear steps, measurable outcomes, governance, ownership - and then teach agents to execute it consistently. This supports a gradual integration approach: embed into existing workflows, measure impact, learn, and improve without disruption.
A Practical Loop for Multi-Agent Maturity
To create real organizational lift, build a repeating loop:
Observe signals from systems and the field
Interpret using ontology - normalize meaning
Decide using policy - constraints, risk, escalation
Act through tools and workflows
Verify outcomes and side effects
Learn by updating procedures, policy, and ontology
This loop is how you cultivate cross-process capabilities - many of them completely new - without losing control or coherence. It also matches the kind of leadership required to make it work: cross-functional delivery, measurable results, and a culture of continuous learning.
Where This Works Best
This approach is especially effective in environments where:
Operations can't be disrupted - manufacturing, municipalities, large organizations
Data is fragmented across systems - ERP, CRM, PLM, service platforms, GIS
Success requires trust, transparency, and explainability
Scaling must be gradual, measurable, and governed
That is exactly why Data Raven emphasizes hands-on integration, system connectivity, security, and building practical foundations like ontology and phased onboarding. We start every engagement by mapping the terms that cross department boundaries - before a single prompt is written.
Call to Action
Multi-agent AI is not a plugin. It's an operating model.
If you want agents that don't just generate output - but reliably improve performance over time - start with the foundations: policy, ontology, and learning procedures.
We run a focused working session to map your policy and ontology foundations before any agent goes into production. If that's the right next step for your organization, let's talk.
Why Ontology Is the Secret to Cross-Domain Scale
Most organizations already have data. What they lack is shared meaning.
Without a common ontology, agents will interpret the same term differently depending on the system or domain they're connected to. That creates silent failures:
"Customer" in CRM ≠ "customer" in billing
"Downtime" in production ≠ "downtime" in maintenance
"Incident" in IT ≠ "incident" in quality
Consider a real case: a product called "Tiger" exists in three systems simultaneously - as a model family in the CRM, as a specific hardware configuration in SAP, and as a software module name in the defect tracking system. An agent pulling context from all three has no way to know these are different things. It will confidently combine information from all three, producing an answer that is internally consistent but factually wrong. No prompt engineering fixes this. The only fix is a shared definition: what "Tiger" means, in which context, and which system is authoritative.
A practical ontology layer solves this by establishing:
A business glossary: canonical terms, synonyms, units, owners
Relationships: entities and how they connect across lifecycle and systems
Rules: KPI definitions, calculation logic, context constraints
Provenance: where numbers come from, when they update, who is accountable
This is why building an organizational data ontology is not "data governance bureaucracy" - it's what enables agents to collaborate across processes without inventing meaning.
The Learning Engine: Procedures That Create a Curve
A multi-agent organization should not be designed as a collection of bots. It should be designed as a learning cycle. That's the difference between short-term automation and long-term capability.
A practical structure is a three-layer stack:
Ontology (Meaning): shared definitions and relationships
Policy (Behavior): guardrails, authority, and auditing
Procedures (Learning & Execution): playbooks and workflows that evolve
Procedures are the scaling unit. When you want to expand to new domains, you don't "copy an agent." You industrialize a procedure: clear steps, measurable outcomes, governance, ownership - and then teach agents to execute it consistently. This supports a gradual integration approach: embed into existing workflows, measure impact, learn, and improve without disruption.
A Practical Loop for Multi-Agent Maturity
To create real organizational lift, build a repeating loop:
Observe signals from systems and the field
Interpret using ontology - normalize meaning
Decide using policy - constraints, risk, escalation
Act through tools and workflows
Verify outcomes and side effects
Learn by updating procedures, policy, and ontology
This loop is how you cultivate cross-process capabilities - many of them completely new - without losing control or coherence. It also matches the kind of leadership required to make it work: cross-functional delivery, measurable results, and a culture of continuous learning.
Where This Works Best
This approach is especially effective in environments where:
Operations can't be disrupted - manufacturing, municipalities, large organizations
Data is fragmented across systems - ERP, CRM, PLM, service platforms, GIS
Success requires trust, transparency, and explainability
Scaling must be gradual, measurable, and governed
That is exactly why Data Raven emphasizes hands-on integration, system connectivity, security, and building practical foundations like ontology and phased onboarding. We start every engagement by mapping the terms that cross department boundaries - before a single prompt is written.
Call to Action
Multi-agent AI is not a plugin. It's an operating model.
If you want agents that don't just generate output - but reliably improve performance over time - start with the foundations: policy, ontology, and learning procedures.
We run a focused working session to map your policy and ontology foundations before any agent goes into production. If that's the right next step for your organization, let's talk.

All rights reserved to Data Raven Technologies